
Como actualmente todos los ordenadores, incluida la pi, tienen varios procesadores o núcleos vamos a ver como usar MPI para acelerar nuestros programas. Mpi (Message Passing Interface) es un protocolo para realizar programación en paralelo. Esto es muy útil ya que se puede usar para que diferentes procesos u aplicaciones se ejecuten en paralelo usando los diferentes núcleos de un ordenador o incluso se ejecuten en diferentes ordenadores en red, acelerando el proceso de los cálculos.
Modelo de Ejecución.
Un programa MPI se lanza como un conjunto de procesos idénticos e independientes. Cada proceso ejecuta exactamente el mismo código de programa y las mismas instrucciones. Como ya comenté, los procesos pueden residir en diferentes núcleos de CPU e incluso en diferentes ordenadores conectados en red.
Se necesita un lanzador especial de MPI para iniciar un programa MPI (mpirun, mpiexec, srun etc). En este capitulo usaremos mpirun.
Rango de MPI.
Cuando se lanza un programa MPI, a cada proceso se le asigna un número de identificación único llamado rango. Es posible consultar el rango dentro de un programa y realizar diferentes tareas en función de él. Sobre este hecho es sobre el que se construye toda la lógica del paralelismo en una aplicación MPI.
La estructura general es la siguiente:
if (rango == 0):
# haz algo
elif (rango == 1):
# haz algo distinto
else:
# todos los demás procesos hacen algo diferente.Comunicador MPI.
Un comunicador es un objeto especial que representa a un grupo de procesos que participan en la comunicación. Cuando se llama a una rutina MPI, la comunicación implicará a algunos o todos los procesos en llamémoslo un comunicador. Todos los procesos comienzan con un comunicador global llamado MPI_COMM_WORLD pero los usuarios también podemos crear nuestros comunicadores personalizados según necesitemos.
Modelo de Datos.
Como todos los procesos son completamente independientes, esto implica también una completa separación de los datos. Cada proceso tiene su propio y separado espacio de memoria, es decir todas las variables y estructura de los datos son locales para ese proceso. Para intercambiar información, los procesos deben enviar y recibir mensajes de forma explícita.

Empecemos.
Esto que parece tan teórico se entiende bastante mejor con un ejemplo práctico. Para empezar vamos a familiarizarnos con dos métodos básicos de comunicación entre objetos:
- Get_size() = Número total de procesos que están presentes en el programa.
- Get_rank() = Rango del proceso dentro de ese comunicador.
Un solo proceso puede pertenecer a varios comunicadores y tener diferente número de rango en cada uno de ellos.
Yo lo estoy probando en Ubuntu 20.04 en el cual el paquete no viene instalado por defecto. Para instalarlo tecleamos:
$ sudo apt-get install -y python3-mpi4pySi lo quieres instalar en un entorno virtual utiliza el comando
(miEntorno_virutal)$ pip install mpi4pyNota: si al instalarlo con este método de da un error puede que te falte la siguiente librería. Instalalá y vuelve a repetir el comando. Tarda un poco porque tiene que compilar algunos archivos.
(miEntorno_virutal)$ sudo apt install libopenmpi-dev # y para que funcione mpirun (miEntorno_virutal)$ sudo apt install openmpi-bin
Una vez hecho lo anterior creamos el siguiente archivo de ejemplo y lo ejecutamos con:
$ python3 hola.py
hola.py: Aplicación de ejemplo
# el objeto comunicador conteniendo todos los objetos.
from mpi4py import MPI
comunicador = MPI.COMM_WORLD
size = comunicador.Get_size()
rank = comunicador.Get_rank()
print("Soy el rango %d en un grupo de %d procesos" % (rank, size))Salida:
Soy el rango 0 en un grupo de 1 procesos
Ejecutando el programa de ejemplo.
Como dije antes, el programa MPI se inicia con un lanzador especial. Al trabajar con Python, el ejecutable que se inicia es el propio interprete de Python. En el ejemplo a continuación, ejecutaremos 4 interpretes de python que ejecutarán el mismo programa hola.py. La comunicación entre los programas se facilitan con las llamadas a la función MPI.
$ mpirun -np 4 python3 hola.pySalida:
Soy el rango 0 en un grupo de 4 procesos
Soy el rango 1 en un grupo de 4 procesos
Soy el rango 3 en un grupo de 4 procesos
Soy el rango 2 en un grupo de 4 procesosEn donde 4 es el número de procesos que ejecutamos de forma simultanea. Si intentas ejecutar más procesos que núcleos tiene tu sistema te dará un error. Por ejemplo, mi máquina soporta 4 núcleos si especifico el mismo comando anterior con un 5 se muestra es siguiente mensaje de error:
"There are not enough slots available in the system to satisfy the 5
slots that were requested by the application"
Lo más importante de la computación en Paralelo.
Las preguntas claves cuando tengamos un trabajo, como por ejemplo sumar una lista enorme de números, serán:
a) ¿ Cómo se puede dividir un problema en partes más pequeñas que se puedan ejecutar en paralelo?
b) ¿Cómo hacerlo de forma eficiente?
Diseñar una buena estrategia para la distribución del trabajo suele ser la parte esencial cuando diseñamos un programa en paralelo. La forma de abordar esta tarea puede ser a través del paralelismo de datos y a través del paralelismo de tareas.
Con el paralelismo de datos lo que haremos será distribuir los datos (de un gran tamaño, como el ejemplo que pusimos de sumar una fila enorme de números) a múltiples procesadores para que luego estos trabajen con los datos en paralelo.
Con el paralelismo de tareas lo que haremos será descomponer el algoritmo en tareas más pequeñas que luego se distribuyen y se ejecutan en paralelo.
Comunicación entre procesos MPI.
Dado que los procesos que intervienen en MPI son independientes uno de otros, para poder realizar su trabajo necesitan comunicarse para enviar y recibir mensajes de forma explicita unos de otros. Hay dos tipos de comunicación en MPI:
1) Comunicación Punto a Punto.
2) Comunicación Colectiva.
En la comunicación "punto a punto" los mensajes se envían entre dos procesos, mientras que en la comunicación colectiva esta se realiza entre varios procesos al mismo tiempo.

Vamos a ver primeramente la comunicación punto a punto.
Comunicación Punto a Punto.
En la comunicación punto a punto un proceso envía un mensaje (algunos datos) a otro proceso que lo recibe. Lo importante es recordar que lo que se envía y lo que se recibe tiene que coincidir. Una recepción por un envio. En un mensaje siempre se envía información a un proceso dado (rango de destino) y de forma similar se recibe de un proceso dado (origen de rango). Funciona un poco como el remitente y el destinatario en los correos.
Veamos lo anterior con un ejemplo de código en el que se envía un diccionario de datos entre dos procesos. Creamos un archivo con el nombre por ejemplo de envio.py
envio.py: Enviamos un diccionario con datos de un proceso a otro.
from mpi4py import MPI
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
if rango == 0:
data = {'a': 7, 'b': 3.14}
comm.send(data, dest=1)
print(f'Datos enviados desde proceso {rango}')
elif rango == 1:
datos_recibidos = comm.recv(source=0)
print(f"En el proceso {rango} hemos recibido lo siguiente")
print(datos_recibidos)y lo ejecutamos con la instrucción, especificando que utilizaremos dos procesos o núcleos:
$ mpirun -np 2 python3 envio.pySalida del programa:
Datos enviados desde proceso 0
En el proceso 1 hemos recibido lo siguiente
{'a': 7, 'b': 3.14}
Enviando y Recibiendo Datos.
Podemos enviar y recibir información o datos entre procesos usando los métodos send() y recv() de un comunicador. Funciona para cualquier objeto de Python que pueda serializarse en un flujo de bytes, es decir, cualquier objeto al que le pueda ser aplicado el módulo pickle. Esto incluye todos los objetos estándar de Python y muchos otros.
La estructura básica de estos métodos es:
.send(datos, destino)
* datos = Objeto de Python a enviar.
* destino = rango o proceso de destino.
.recv(fuente)
* fuente = proceso o rango origen del mensaje. Los datos se proporcionan como valor de retorno.
Las rutinas normales de envió y recepción se bloquean, es decir la función solamente finaliza cuando es seguro utilizar los datos (la memoria) involucrada en la comunicación. Esto significa la finalización va a depender de un proceso diferente al que lo inicio y esto provoca que exista el riesgo de que se bloque el programa. Por ejemplo si ambos procesos ejecutan el método .recv() a lo primero, no quedará ninguno que pueda ejecutar el send() correspondiente con lo que el programa se atascará para siempre.
A continuación mostraré los patrones típicos de la comunicación punto a punto. Un orden incorrecto en los procesos de envió y recepción de los mensajes puede dar lugar a que el programa se quede en un punto muerto.
Intercambio por parejas.
Un anillo de procesos intercambiando datos.

Comunicación rápida de grandes arrays o cantidades de datos.
MPI para Python ofrece rutinas muy buenas y flexibles para enviar y recibir objetos generales de Python. Por desgracia esta flexibilidad tiene un coste en rendimiento. En la práctica lo que está sucediendo internamente es que los objetos de Python se convierten en flujos de bytes al enviarlos (pickled) y estos se vuelven a convertir en objetos al recibirse (unpickled). Esta conversión/desconversión puede generar lentitud en la comunicación de los datos. Lo bueno es que MPI para Python nos ofrece unos métodos alternativos para enviar y recibir fragmentos de memoria contiguos (como matrices o arrays de Numpy)
Esto viene a cuento de que anteriormente para enviar y recibir información hemos utilizado los métodos "send()" y "recv()" en minúsculas. Sin embargo es más recomendable hacerlo usando los mismos nombres pero comenzando su primera letra por mayúsculas "Send()"y "Recv()". ¿Por qué?
Pues porque MPI distingue entre dos tipos de comandos. Mientras que las que comienzan por minúscula hacen referencia a las rutinas de uso múltiple o general, que requieren convertir los datos en bytes, las que lo hacen empezando con mayúsculas permiten copiar bloques de memoria sin conversiones. Esto hace que si la cantidad de datos a comunicar entre procesos es muy grande, se produzca una enorme mejora en el rendimiento. Por lo tanto siempre es recomendable utilizar los métodos que comienzan por mayúsculas.
Enviar / Recibir arrays o matrices de Numpy.
Enviar y recibir una matriz de Numpy de forma eficiente es extremadamente sencillo. MPI para python se lleva muy bien con la librería Numpy y se encargará automáticamente de la mayoría de los detalles.
Para realizar un envío solamente tenemos que utilizar el método Send() con la primera letra en mayúsculas dando la matriz de Numpy y el rango o proceso de destino como argumentos.
Send(datos, dest)Para recibir los datos primeramente tenemos que preparar una matriz o array de Numpy y luego usar el método Recv() en mayúsculas pasándole como argumentos la matriz de Numpy y el número del rango o proceso de origen.
datos = numpy.empty(forma del array, dtype)
Recv(datos, source)¡Ten en cuenta la diferencia que existe entre usar los datos con mayúsculas o minúsculas desde el lado de la recepción! Recv() en mayúsculas no devuelve datos, sino que los copia en una matriz existente. Por eso previamente tenemos que preparar la matriz.
Veamos un ejemplo.
envioNumpy.py: Enviamos una matriz numpy de un proceso a otro
from mpi4py import MPI
# Importamos la libreria Numpy para poder mandar el array.
import numpy
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
# Inicializamos un nuevo array con 100 valores sin inicializar o asignar las entradas,
# del tipo float.
data = numpy.empty(100, dtype=float)
if rango == 0:
# Asignamos a la matriz que ya tenemos creada valores en un rango del 0 al 99. 100 items
data[:] = numpy.arange(100, dtype=float)
# Los enviamos al proceso 1
comm.Send(data, dest=1)
print(f"El proceso {rango} ha enviado la matriz")
elif rango == 1:
comm.Recv(data, source=0)
print(f"Proceso {rango}: matriz recibida -> {data}")
# Ejecutamos dos rangos o procesos.
$ mpirun -np 2 python3 envioNumpy.py Salida:
El proceso 0 ha enviado la matriz
Proceso 1: matriz recibida -> [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17.
18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35.
36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53.
54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71.
72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89.
90. 91. 92. 93. 94. 95. 96. 97. 98. 99.]Combinando envíos y recepciones de datos.
MPI también soporta el envió de un mensaje y la recepción de otro con un solo comando. Esto reduce le riesgo de bloqueo del programa en las situaciones más habituales. Por ejemplo, cuando se realiza un simple intercambio de mensajes entre dos procesos (es decir dos procesos envían y reciben un mensaje entre si) hay que tener cuidado en que un proceso primero envíe y el otro reciba y viceversa para evitar bloqueos en el programa. Con una combinación tanto de envió como de recepción en un solo comando podemos evitar este problema.
Este método se llama Sendrecv() y es la combinación de send() y de recv() en un solo comando. Su estructura es la siguiente.
buffer = numpy.empty(data.shape, dtype=data.dtype)
Sendrecv(data, dest=rango_destino, recvbuf=buffer, source=rango_origen)Los rango de destino (al que mandamos el mensaje) y origen (desde el que recibimos el mensaje) pueden ser el mismo o ser diferentes. Si no se quiere poner el destino o la fuente (por ejemplo porque estemos en los rangos límite (proceso 0 y proceso 3),
se pude especificar MPI.PROC_NULL para indicar que en esos procesos no hay comunicación. Al igual que cuando usamos Recv() con mayúsculas el buffer para recibir los datos debe existir antes de la llamada y ser lo suficientemente grande para contener todos los datos que se recibirán.
Veamos esto tan farragoso con un ejemplo. Vamos a mandar y recibir simultáneamente dos matrices de numpy entre dos procesos.
El proceso 0 enviará el siguiente array de 10 elementos al 1:
[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
y para diferenciarlo del anterior, el proceso 1 enviará al 0 el mismo array pero multiplicado por 2:
[ 0. 2. 4. 6. 8. 10. 12. 14. 16. 18.]
El código del programa sería:
Sendrecv.py: Envio y recepción mediante una sola instrucción
from mpi4py import MPI
# Importamos la libreria Numpy para poder mandar el array.
import numpy
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
# Creamos el array a enviar en función del rango o proceso, con 10 items
data = numpy.arange(10, dtype=float) * (rango + 1)
# Creamos el buffer de almacenamiento necesario para que nos pete el programa.
buffer = numpy.empty(10, float)
# Creamos la parte lógica
if rango == 0:
rango_destino, rango_origen = 1, 1
print(f"El proceso {rango} ha enviado la matriz \n {data}")
elif rango == 1:
rango_destino, rango_origen = 0, 0
print(f"El proceso {rango} ha enviado la matriz \n {data}")
comm.Sendrecv(data, dest=rango_destino, recvbuf=buffer, source=rango_origen)
print(f"El proceso {rango} recibió el siguiente array \n {buffer}")
Ejecutamos nuestro programa mediante la instrucción para dos procesos:
$ mpirun -np 2 python3 Sendrecv.py y obtenemos la siguiente salida:
El proceso 1 ha enviado la matriz
[ 0. 2. 4. 6. 8. 10. 12. 14. 16. 18.]
El proceso 0 ha enviado la matriz
[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
El proceso 0 recibió el siguiente array
[ 0. 2. 4. 6. 8. 10. 12. 14. 16. 18.]
El proceso 1 recibió el siguiente array
[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]Si no hubiéramos usado la instrucción única Sendrecv(), el mismo ejemplo usando Send() y Recv() sería el siguiente:
Send_Recv.py: Envio y recepción mediante dos instrucciones
from mpi4py import MPI
# Importamos la libreria Numpy para poder mandar el array.
import numpy
'''Para funcionar con numpy y MPi se usan los metodos con la primera letra en mayusculas
porque funcionan de forma distinta que para el resto de objetos'''
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
# Creamos el array a enviar en función del rango o proceso, con 10 items
data = numpy.arange(10, dtype=float) * (rango + 1)
# Creamos el buffer de almacenamiento necesario para que nos pete el programa.
buffer = numpy.empty(10, float)
# Creamos la parte lógica pero usando Send() y Recv()
# Importante el orden, rango 0 envia y 1 recibe y luego 1 envia y 0 recibe
if rango == 0:
comm.Send(data, dest=1)
print(f"El proceso {rango} ha enviado la matriz \n {data}")
comm.Recv(buffer, source=1)
print(f"El proceso {rango} recibió el siguiente array \n {buffer}")
elif rango == 1:
comm.Recv(buffer, source=0)
print(f"El proceso {rango} recibió el siguiente array \n {buffer}")
comm.Send(data, dest=0)
print(f"El proceso {rango} ha enviado la matriz \n {data}")Ejecutamos nuestro programa mediante la instrucción para dos procesos:
$ mpirun -np 2 python3 Send_Recv.py y obtenemos la siguiente salida:
El proceso 0 ha enviado la matriz
[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
El proceso 1 recibió el siguiente array
[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
El proceso 1 ha enviado la matriz
[ 0. 2. 4. 6. 8. 10. 12. 14. 16. 18.]
El proceso 0 recibió el siguiente array
[ 0. 2. 4. 6. 8. 10. 12. 14. 16. 18.]Como podemos observar todo está perfectamente coordinado.
Comunicación sin Bloqueo.
Hasta ahora, hemos estado utilizando rutinas de comunicación con bloqueo, es decir el programa está bloqueado esperando que se lleve a cabo la comunicación y se sigue ejecutando cuando esta se realiza. Las rutinas que bloquean el programa terminarán solo cuando sea seguro acceder a los datos involucrados en la comunicación.
Aunque algunas implementaciones de MPI pueden, por ejemplo, almacenar en cache los datos que se enviarán y liberar el envío "Send" antes de que se produzca la recepción Recv(), no está garantizado que el programa no se bloquee y ciertamente no es algo en que se pueda confiar.
Sin embargo, MPI también admite la comunicación sin bloqueo, en la que la comunicación se realiza en segundo plano mientras que el procesador es libre de realizar alguna tarea mientras tanto. Estas tareas pueden ser, por ejemplo, realizar algunos cálculos de forma local mientras espera a que finalice alguna sincronización con los procesos vecinos.
Las diferencias claves con respecto a la comunicación con bloqueo son:
- Aquí los métodos se llamarán isend(), irecv(), Isend() etc. Se les antepone la letra "i" antes de los nombres de los métodos que ya hemos visto.
- La llamada regresará inmediatamente ya que la comunicación se realiza en segundo plano.
- El valor que se retorna es un objeto de la solicitud.
El uso de la comunicación sin bloqueo permite que la computación de los datos y su comunicación se realicen de forma simultánea y se eviten muchas situaciones habituales de interbloqueo entre procesos.
La comunicación sin bloqueo suele ser la forma más eficiente de hacer la comunicación punto a punto en MPI.
Finalizar la Comunicación.
Toda comunicación sin bloqueo debe finalizar en algún momento. Podemos esperar que la comunicación termine o bien comprobar su estado actual.
Si queremos esperar a que termine la comunicación iniciada con isend() o irecv() (o Isend() etc) podemos usar el método wait(). Es una llamada de bloqueo que esperará a que la comunicación referida por el objeto de la solicitud finalice.
Para probar si una comunicación sin bloqueo ha finalizado o no podemos usar el método test(). Nos devolverá True si la comunicación ha finalizado y False en caso contrario. Este estado (Verdadero o Falso) está contenido en una Tupla de Python en donde el segundo elemento es el valor de retorno de la llamada MPI. Por ejemplo para un comando irecv() que este finalizado esta tupla contendrá los datos recibidos mientras que para un comando Irecv() el resultado será None.
Podemos usar en una comunicación punto a punto, tanto la comunicación con bloqueo como sin bloqueo. Vamos que es perfectamente correcto usar recv() para recibir un mensaje que se ha enviado con isend().
Vamos a ver un ejemplo de lo que hemos dicho.
non_blocking.py: Envío y recepción por comunicación sin bloqueo.
from mpi4py import MPI
# Importamos la libreria Numpy para poder mandar el array.
import numpy
N = 10_000_000 # Enviamos una array con este numero de elementos
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
procesos = comm.Get_size()
# Creamos el array a enviar en función del rango o proceso, con 100 items
data = numpy.arange(N, dtype=float) * (rango + 1)
if rango == 0:
req = comm.Isend(data, dest=1) # Empezando a enviar
#calculate_something(rango) # .. haciendo algo mas ..
print("El proceso 0 esta mandando los datos")
print(f"He mandado una matriz de {data.size} elementos")
req.wait() # esperamos a que el envio termine
# ya es seguro leer/escribir los datos de nuevo
elif rango == 1:
data = numpy.empty(N, float)
req = comm.Irecv(data, source=0) # datos a recibir
#calculate_something(rango) # .. haciendo algo mas ..
print("El proceso 1 esta recibiendo los datos")
print(f"La matriz recibida tiene {data.size} elementos")
req.wait() # esperamos a que llegue todo para terminar
# Los datos están listos para usarse.Ejecutamos nuestro programa mediante la instrucción para dos procesos:
$ mpirun -np 2 python3 non_blocking.py y obtenemos la siguiente salida:
El proceso 0 esta mandando los datos
He mandado una matriz de 10000000 elementos
El proceso 1 esta recibiendo los datos
La matriz recibida tiene 10000000 elementosVarias Operaciones sin bloqueo.
Las funciones waitall() y waitany() nos pueden resultar útiles cuando se utilizan varios procesos comunicándose sin bloqueo. Como sus nombres indican waitall() esperará a que todas las peticiones se completen y waitany() esperará que una de las peticiones enviadas se complete.
Por ejemplo se puede esperar a que todas las solicitudes terminen con:
MPI.Request.waitall(peticiones)
Veamos un ejemplo.
varios.py: Envío y recepción por comunicación sin bloqueo simultanea varios procesos.
from mpi4py import MPI
import numpy
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
size = comm.Get_size()
data = numpy.arange(10, dtype=float) * (rango + 1) # send buffer
buffer = numpy.zeros(10, dtype=float) # receive buffer
print(f"Rango {rango} iniciado")
destino = rango + 1
origen = rango - 1
if rango == 0:
origen = MPI.PROC_NULL
if rango == size - 1:
destino = MPI.PROC_NULL
peticiones = []
peticiones.append(comm.Isend(data, dest=destino))
print(f"Rango {rango} enviando datos al rango {destino}")
peticiones.append(comm.Irecv(buffer, source=origen))
print(f"Rango {rango} recibiendo datos de rango {origen}")
MPI.Request.waitall(peticiones)Ejecutamos nuestro programa mediante la instrucción para 4 procesos:
$ mpirun -np 4 python3 varios.py Obtenemos la siguiente salida:
Rango 1 iniciado
Rango 1 enviando datos al rango 2
Rango 1 recibiendo datos de rango 0
Rango 0 iniciado
Rango 0 enviando datos al rango 1
Rango 0 recibiendo datos de rango -2
Rango 2 iniciado
Rango 2 enviando datos al rango 3
Rango 2 recibiendo datos de rango 1
Rango 3 iniciado
Rango 3 enviando datos al rango -2
Rango 3 recibiendo datos de rango 2
Comunicadores.
Dentro del entorno MPI, un comunicador es un objeto especial que representa a un grupo de procesos que participan en la comunicación. Cuando ejecutamos una rutina MPI, la comunicación implicará a algunos o a todos los procesos del comunicador.
En otros lenguajes de programación, todas las rutinas MPI esperan un comunicador como uno de sus argumentos. En Python, las mayoría de las rutinas MPI se implementan como métodos de un objeto comunicador.
Hasta el momento en todos los ejemplos los procesos pertenecían a un único comunicador pero esto no tiene porque ser así. Un proceso puede pertenecer a varios comunicadores y tendrá un ID único (rango) en cada uno de ellos.

Comunicadores definidos por el usuario.
Todos los procesos comienzan en un comunicador global llamado MPI_COMM_WORLD (o MPI.COMM_WORLD en mpi4py) pero también podemos definir nuestros propios comunicadores si lo necesitamos.
De forma predeterminada, existe un único comunicador global al que pertenecen todos los procesos (MPI.COMM_WORLD). Podemos crear un nuevo comunicador a partir de uno ya existente. Por Ejemplo, si quisiéramos dividir los procesos de un comunicador en subgrupos más pequeños, se podría hacer los siguiente:
comm.py: Uso de comunicadores personalizados. 2 en este ejemplo a partir de un grupo de 4 procesos.
from mpi4py import MPI
# Creamos el comunicador global
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
# repartiremos los procesos del comunicador global en 2 subgrupos el 0 y el 1
grupo = rango % 2 # % es el resto de una división
# 0 % 2 => 0 ; 1 % 2 => 1 ; 2 % 2 => 0 y 3 % 2 => 1
comm_local = comm.Split(grupo)
rango_local = comm_local.Get_rank()
print(f"Rango global: {rango} ; Rango local: {rango_local} del subgrupo: {grupo}")Ejecutamos nuestro programa mediante la instrucción para 4 procesos:
$ mpirun -np 4 python3 comm.pySalida:
Rango global: 0 ; Rango local: 0 del subgrupo: 0
Rango global: 1 ; Rango local: 0 del subgrupo: 1
Rango global: 2 ; Rango local: 1 del subgrupo: 0
Rango global: 3 ; Rango local: 1 del subgrupo: 1En este ejemplo, asignamos una etiqueta distinta (llamada grupo, que es en realidad o el número 0 o el 1) a cada proceso en función de su rango en el comunicador global. Luego se crean los nuevos comunicadores en base a ese valor, para que todos los procesos del mismo grupo acaben asignados a su nuevo comunicador. En este ejemplo se dividen los 4 procesos del comunicador original en 2 subgrupos, cada uno de los cuales comparte un nuevo comunicador dentro del subgrupo.
Comunicación Colectiva: de uno a varios.
En este tipo de comunicación se transfieren datos entre todos los procesos de un comunicador. MPI incluye rutinas, no solo para el movimiento de datos, sino también para realizar computación colectiva y sincronización de los procesos. Por ejemplo, se suele usar con frecuencia el método sobre el comunicador, comm.barrier(), que hace que cada tarea se mantenga hasta que todas las tareas del comunicador la hayan llamado.
Dada que estas tareas son colectivas, deben ser llamadas por todos los procesos del comunicador. Además la cantidad de datos enviados y recibidos debe coincidir. Las ventajas de utilizar la comunicación colectiva frente a la individual es que el código se vuelve más compacto y más fácil de mantener, lo cual es una gran ventaja para el programador.
La comunicación colectiva suele ser más eficaz para resolver problemas que la comunicación punto a punto y de hecho suele ser la forma más frecuentemente usada en la comunicación MPI. Por ejemplo comunicar, una matriz Numpy de la tarea 0 a todas las demás se simplifica pasando de ser un código como:
if rango == 0:
for i in range(1, total_procesos):
comm.Send(data, i)
else:
comm.Recv(data, 0)a una sola línea de código:
comm.Bcast(data, 0)Vamos a ver primero como utilizar la comunicación colectiva para transmitir datos de un proceso a todos los demás, es decir cómo mover datos de uno a varios.
Broadcast (Transmisión) - Bcast
En la transmisión se envían los mismos datos desde el proceso de origen a todos los demás. Lo que se hace es replicar ese dato en todos los procesos para que estos lo tengan disponible localmente.

broadcast.py: Envío y recepción por comunicación colectiva.
from mpi4py import MPI
import numpy
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
if rango == 0:
py_data = {'item1' : 0.0, 'item2' : 11}
# un diccionario de python
data = numpy.arange(8) / 10.
# array numpy = [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7]
print(f"Rango {rango}: enviando {py_data} y {data}")
else:
py_data = None # Python object
data = numpy.zeros(8) # numpy array
new_data = comm.bcast(py_data, root=0)
comm.Bcast(data, root=0)
if rango != 0:
print(f"Rango {rango}: recibiendo {new_data}, {data}")Ejecutamos nuestro programa mediante la instrucción para 4 procesos:
$ mpirun -np 4 python3 broadcast.pySalida:
Rango 0: enviando {'item1': 0.0, 'item2': 11} y [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7]
Rango 1: recibiendo {'item1': 0.0, 'item2': 11}, [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7]
Rango 3: recibiendo {'item1': 0.0, 'item2': 11}, [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7]
Rango 2: recibiendo {'item1': 0.0, 'item2': 11}, [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7]Scatter. (dispersión)
Scatter envía una cantidad igual de datos desde un proceso a todos los demás procesos. Se utiliza para distribuir los datos por igual entre todos los procesos.

Los segmentos A, B, etc pueden tener múltiples elementos.
Un ejemplo de reparto puede ser mandar una lista de números (un número para cada tarea) y una matriz de Numpy (multiples elementos para cada tarea)
scatter.py: Reparto igualitario de datos entre procesos.
from mpi4py import MPI
from numpy import arange, empty
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
size = comm.Get_size()
if rango == 0:
# lista con el mismo número de elementos que procesos tengamos
py_data = range(size)
# matriz de numpy a enviar.
data = arange(size**2, dtype=float)
print(f"Proceso {rango} enviando {py_data} y {data}")
else:
py_data = None
data = None
new_data = comm.scatter(py_data, root=0) # devuelve el valor
buffer = empty(size, float) # prepara para recibir el buffer
comm.Scatter(data, buffer, root=0) # modificación en el lugar
if rango!=0:
print(f"Proceso {rango} recibiendo {new_data} y {buffer}")
Ejecutamos nuestro programa mediante la instrucción para 4 procesos:
$ mpirun -np 4 python3 scatter.pySalida:
Proceso 0 enviando range(0, 4) y [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15.]
Proceso 2 recibiendo 2 y [ 8. 9. 10. 11.]
Proceso 3 recibiendo 3 y [12. 13. 14. 15.]
Proceso 1 recibiendo 1 y [4. 5. 6. 7.]Comunicación Colectiva: de varios a uno.
Lo siguiente que vamos a ver es como utilizar la comunicación colectiva para recopilar datos de todas las tareas y mandarla a una sola.
Gather - Recolectar.
La instrucción Gather recopila la misma cantidad de datos de todos los procesos implicados en la comunicación a un único proceso. Podemos pensar que es justo lo contrario que vimos en el punto anterior con la instrucción Scatter. P.ej. nos pude servir para recopilar resultados parciales de las tareas.

gather.py: Recopilación de datos varios procesos en uno solo.
from mpi4py import MPI
from numpy import arange, zeros
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
size = comm.Get_size()
data = arange(5, dtype=float) * (rango + 1)
buffer = zeros(size * 5, float)
n = comm.gather(rango, root=0) # devuelve el valor
comm.Gather(data, buffer, root=0) # modificación en el lugar.
if rango == 0:
print(f"Rango {rango}, lista recogida: {n}, matriz: {buffer}")
else:
print(f"Rango {rango}, nº lista {rango}, trozo matriz: {data}")Ejecutamos nuestro programa mediante la instrucción para 4 procesos:
$ mpirun -np 4 python3 gather.pySalida:
Rango 1, nº lista 1, trozo matriz: [0. 2. 4. 6. 8.]
Rango 0, lista recogida: [0, 1, 2, 3], matriz: [ 0. 1. 2. 3. 4. 0. 2. 4. 6. 8. 0. 3. 6. 9. 12. 0. 4. 8.
12. 16.]
Rango 2, nº lista 2, trozo matriz: [ 0. 3. 6. 9. 12.]
Rango 3, nº lista 3, trozo matriz: [ 0. 4. 8. 12. 16.]Reduce - Reducir.
Este comando recopila datos de todos los procesos existentes en un comunicador y aplica una operación sobre los datos antes de almacenar el resultado en un único proceso. Básicamente es como el ejemplo anterior - gather - pero realizando una operación previa a mayores.
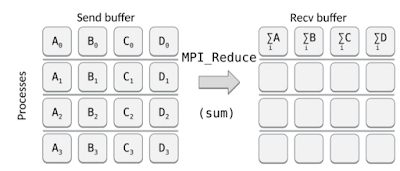
La aplicación que se aplica a los datos puede ser cualquier cosa. Desde una suma, a un procesador lógico, etc. MPI admite una amplia variedad de operaciones que se pueden utilizar, entre otros:
- MPI.MAX - valor máximo
- MPI.MIN - valor mínimo
- MPI.SUM - suma de los datos.
- MPI.PROD - producto de los datos.
Vamos a ver un ejemplo en el que se sume los datos de los procesos antes de ser enviado a un único miembro. Sumaremos una lista que será el número de cada proceso (0+1+2+3) y una matriz Numpy de cada proceso:
reduce.py: Recopilación de datos varios procesos en uno solo, con una operación previa.
from mpi4py import MPI
from numpy import arange, zeros
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
size = comm.Get_size()
data = arange(5 * size, dtype=float) * (rango + 1)
buffer = zeros(size * 5, float)
n = comm.reduce(rango, op=MPI.SUM, root=0) # retorna el valor
comm.Reduce(data, buffer, op=MPI.SUM, root=0) # modificación en el lugar.
if rango == 0:
print(f"Rango {rango}, suma recogida: {n}, matriz suma: {buffer}")
else:
print(f"Rango {rango}, nº lista: {rango}, trozo matriz: {data}")Ejecutamos nuestro programa mediante la instrucción para 4 procesos:
$ mpirun -np 4 python3 reduce.pySalida:
Rango 0, suma recogida: 6, matriz suma: [ 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100. 110. 120. 130.
140. 150. 160. 170. 180. 190.]
Rango 1, nº lista: 1, trozo matriz: [ 0. 2. 4. 6. 8. 10. 12. 14. 16. 18. 20. 22. 24. 26. 28. 30. 32. 34.
36. 38.]
Rango 2, nº lista: 2, trozo matriz: [ 0. 3. 6. 9. 12. 15. 18. 21. 24. 27. 30. 33. 36. 39. 42. 45. 48. 51.
54. 57.]
Rango 3, nº lista: 3, trozo matriz: [ 0. 4. 8. 12. 16. 20. 24. 28. 32. 36. 40. 44. 48. 52. 56. 60. 64. 68.
72. 76.]allreduce.py: Al final todos los procesos tienen los resultados de los datos que se les pasan.
from mpi4py import MPI
from numpy import arange, empty
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
size = comm.Get_size()
data = arange(10 * size, dtype=float) * (rango + 1)
buffer = empty(size * 10, float)
n = comm.allreduce(rango, op=MPI.SUM) # retorna el valor de la suma
comm.Allreduce(data, buffer, op=MPI.SUM) # realiza la modificación en el lugar
print(f"Rango {rango}; la suma de todos los rangos es: {n} \ny la suma de la matriz numpy es: {buffer}")Ejecutamos nuestro programa mediante la instrucción para 4 procesos:
$ mpirun -np 4 python3 reduce.pySalida:
Rango 3; la suma de todos los rangos es: 6
y la suma de la matriz numpy es: [ 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100. 110. 120. 130.
140. 150. 160. 170. 180. 190. 200. 210. 220. 230. 240. 250. 260. 270.
280. 290. 300. 310. 320. 330. 340. 350. 360. 370. 380. 390.]
Rango 0; la suma de todos los rangos es: 6
y la suma de la matriz numpy es: [ 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100. 110. 120. 130.
140. 150. 160. 170. 180. 190. 200. 210. 220. 230. 240. 250. 260. 270.
280. 290. 300. 310. 320. 330. 340. 350. 360. 370. 380. 390.]
Rango 1; la suma de todos los rangos es: 6
y la suma de la matriz numpy es: [ 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100. 110. 120. 130.
140. 150. 160. 170. 180. 190. 200. 210. 220. 230. 240. 250. 260. 270.
280. 290. 300. 310. 320. 330. 340. 350. 360. 370. 380. 390.]
Rango 2; la suma de todos los rangos es: 6
y la suma de la matriz numpy es: [ 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100. 110. 120. 130.
140. 150. 160. 170. 180. 190. 200. 210. 220. 230. 240. 250. 260. 270.
280. 290. 300. 310. 320. 330. 340. 350. 360. 370. 380. 390.]
alltoall.py: cada proceso envia y recibe información.
from mpi4py import MPI
from numpy import arange, empty, zeros_like
comm = MPI.COMM_WORLD
rango = comm.Get_rank()
size = comm.Get_size()
py_data = range(size)
data = arange(size**2, dtype=float)
new_data = comm.alltoall(py_data) # devuelve el valor
buffer = zeros_like(data) # prepara al programa para recibir el buffer
comm.Alltoall(data, buffer) # modificación al vuelo.
print(f"Rango {rango}, {py_data}, {new_data}\n{data}\{buffer}")Ejecutamos nuestro programa mediante la instrucción para 4 procesos:
$ mpirun -np 4 python3 reduce.pySalida:
Rango 1, range(0, 4), [1, 1, 1, 1]
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15.]\[4. 5. 6. 7. 4. 5. 6. 7. 4. 5. 6. 7. 4. 5. 6. 7.]
Rango 2, range(0, 4), [2, 2, 2, 2]
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15.]\[ 8. 9. 10. 11. 8. 9. 10. 11. 8. 9. 10. 11. 8. 9. 10. 11.]
Rango 3, range(0, 4), [3, 3, 3, 3]
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15.]\[12. 13. 14. 15. 12. 13. 14. 15. 12. 13. 14. 15. 12. 13. 14. 15.]
Rango 0, range(0, 4), [0, 0, 0, 0]
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15.]\[0. 1. 2. 3. 0. 1. 2. 3. 0. 1. 2. 3. 0. 1. 2. 3.]Errores más comunes en la Comunicación colectiva entre procesos.
- Usar una operación colectiva dentro de una instrucción if-else basándonos en el rango del proceso.
if rango == 0:
comm.broadcast(.............)
Hay que recordar que todos los procesos deben llamar a la rutina colectiva. - Suponer que todos los procesos que están realizando una llamada colectiva se completan al mismo tiempo. Incluso usando la comunicación colectiva a través de MPI, solo se nos asegura que el proceso sigue vivo hasta que todos los demás terminan la llamada. Con las instrucciones de movimiento de datos (scatter, bcast etc) esto puede incluso no ser cierto, ya que MPI solo garantiza que el proceso continuará solo cuando sea seguro hacerlo. Las instrucciones de MPI pueden, y de hecho lo hacen, usar caches de comunicación que permitan a algunos de los procesos continuar desde una llamada colectiva incluso antes de que ocurra la comunicación.
- Usar el búfer de entrada de datos también como búfer de salida.
comm.Scatter(a, a, MPI.SUM)
¡Hay que utilizar siempre diferentes ubicaciones de memoria (matrices) de entrada y de salida!















